通过 NVIDIA TAO 5.5 实现全新基础模型和增强训练功能,助力深度学习领域创新发展
NVIDIA TAO 是一个用于简化和加速 AI 模型开发与部署的框架。有了它,您无需具备深厚的 AI 专业知识,就可以使用预训练模型、利用自己的数据对这些模型进行微调,并针对特定用例优化这些模型。
TAO 能够与 NVIDIA 软硬件生态系统无缝集成,提供实现高效 AI 模型训练、部署和推理的工具,加快 AI 驱动型应用的上市时间。
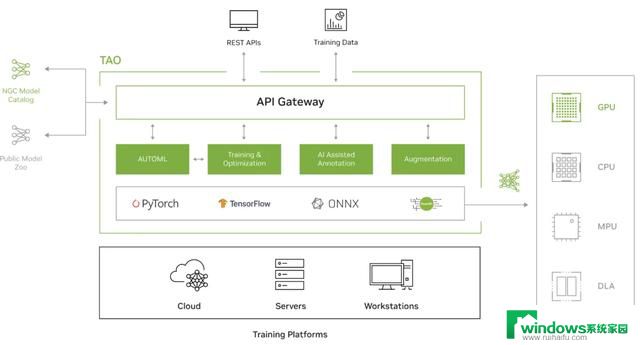
图 1. NVIDIA TAO 架构
图 1 显示 TAO 支持 PyTorch、TensorFlow 和 ONNX 等框架。可以在多个平台上完成训练,生成的模型可以部署在各种推理平台上,例如 GPU、CPU、MCU 和 DLA。
NVIDIA 最近发布的 TAO 5.5 带来了最先进的基础模型和开创性的功能,加强了一切 AI 模型的开发。新功能包括:
在本文中,我们将更加详细地讨论 TAO 5.5 的新功能。
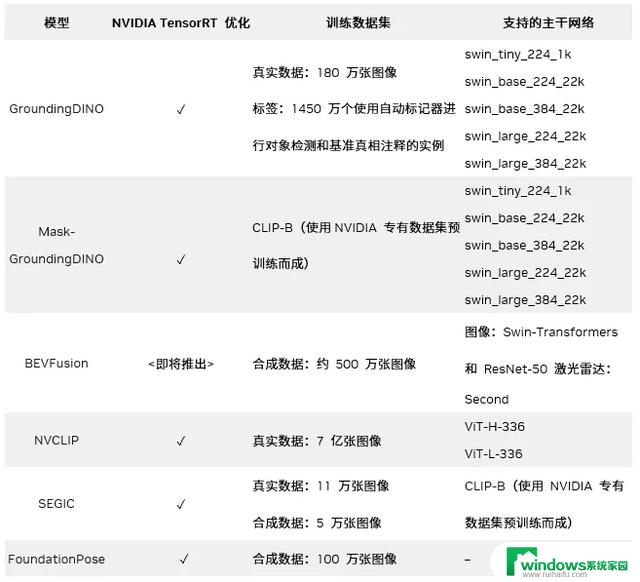
表 1. TAO 5.5 中的新基础模型和多模态模型
NVIDIA TAO 集成了开源模型、基础模型和专有模型,这些模型均在大量专有数据集和商用数据集上训练而成,因此在对象检测、姿态检测、图像分类、分割等任务中具有广泛的用途。TAO 简化了针对特定用例微调这些模型的过程,以使它们的定制和商业化落地变得容易。
大多数模型均通过 NVIDIA TensorRT 加速,并针对 NVIDIA 硬件的性能进行优化,保证了 AI 解决方案的强大与高效。
在 TAO 中更换模型骨干网络非常简单,无需编码,只需简单更改配置即可。凭借这种灵活性,您可以尝试不同的架构,例如 ResNet、移位窗口(Swin) Transformer 和全注意力网络(FAN)等,根据特定需求定制模型。
这种便利的定制能力能够为各种应用提供助力,例如零售业的产品识别、医疗行业的医学影像分类、制造业的机器人装配监控、智慧城市的交通管理等。
GroundingDINO 模型
通过 NVIDIA TAO 5.5 实现全新基础模型和增强训练功能
传统的对象检测模型只能识别预定义类别中的对象(封闭集检测)。这一局限性使它们无法满足根据人类输入内容(如特定类别名称或详细引用表述)来识别任意对象的应用需求。
GroundingDINO 解决这一局限性的方法是把文本编码器集成到 DINO 模型中,从而将其转换成开放集对象检测器。这样,该模型就能检测到人类输入内容所描述的任何对象。
通过采用特征增强器、语言引导的查询选择和跨模态解码器,GoundingDINO 有效地融合了语言与视觉模态,这使该模型能够概括超出预定义类别的概念,实现卓越的性能。
通过 TAO 实现的 GroundingDINO
该模型通过 Swin-Tiny 骨干网络在 NVIDIA 专有的商用数据集上以有监督的方式训练而成。此外,还使用了 BERT-Base 作为文本塔的起始权重。最后, GroundingDINO 在从公开数据集采集的约 180 万张图像上进行了端到端训练。
训练中使用的所有原始图像均取得商业许可证,保证了商业使用的安全。

表 2. GroundingDINO 在 COCO 验证数据集上的关键性能指标
Mask-GroundingDINO 模型
Mask-GroundingDINO 是一种单阶段、开放词汇实例分割模型,可围绕一个对象的特定实例生成分割掩码。该模型建立在 GroundingDINO 架构的基础上,并使用实例分割条件卷积(CondInst)启发分割图。
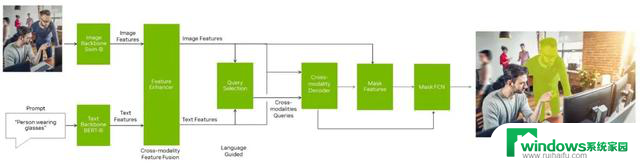
图 2. Mask-GroundingDINO 模型架构
通过 TAO 实现的 Mask-GroundingDINO
CondInst 提出了一种用于实例分割的条件卷积头,它能根据输入内容或特征图更新卷积内核权重。我们将 CondInst 中原本只为 CNN 设计的掩码分支和实例感知掩码头扩展到 Transformer 或基于查询的模型。
在 Mask-GroundingDINO 中,我们选择使用与 DINO 相同的编码器和解码器设计,但仍可以与其他 Transformer 编码器和解码器进行类似的连接。
该模型在伪标签开放图像数据集上,使用 GroundingDINO 商用预训练模型进行了微调,因此可用于商业用途。该模型使用 Swin-Tiny 骨干网络,其分割头在约 83 万张具有伪标签基准真相掩码的图像上进行了端到端微调。
您可以按原样使用该模型,也可以使用 TAO 对其进行微调。为了进行微调,我们提供了 Mask-GroundingDINO Jupyter notebook,该 notebook 提供了一个编码要求极低的简单交互式环境。

表 3. Mask-GroundingDINO 在 COCO 验证数据集上的关键性能指标
BEVFusion 模型
通过 NVIDIA TAO 5.5 实现全新基础模型和增强训练功能
无论是自动驾驶,还是机器人和智慧城市,许多领域的系统都依靠各种传感器感知环境并与之互动。每一类传感器,如摄像头、激光雷达或雷达等,都能提供特别的信息,但同时也存在各自固有的局限性。例如摄像头虽然能够捕捉丰富的视觉细节,但在深度感知方面却很吃力;而激光雷达虽然在测量距离方面表现出色,但缺乏语义背景。
目前面临的难题是如何有效结合这些不同的数据源,来提高系统性能和可靠性。
BEVFusion 解决这一难题的办法是将来自多个传感器的数据整合到一个统一的鸟瞰图(BEV)表示方法中。它在保留几何(来自激光雷达)和语义(来自摄像头)信息的情况下,将多模态特征统合到一个共享的 BEV 表示方法中,彻底改变了这一过程。
通过 TAO 实现的 BEVFusion
在 TAO 中,我们从 mmdet3d 的 BEVFusion 代码库开始训练我们的模型。我们对原代码进行了改进,以便处理 3D 空间中的三个角度(翻滚、俯仰和偏航),而最初它只支持俯仰。TAO 训练的 BEVFusion 模型能在单个摄像头视图和激光雷达内检测到人,并在人周围创建一个 3D 边界框。
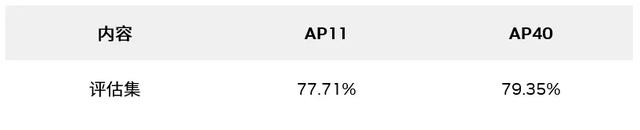
表 4. TAO BEVFusion 在 COCO 验证数据集上的 单摄像头、单激光雷达人员检测的关键性能指标
CLIP 模型
高效学习有意义且上下文丰富的图像和文本表示方法是一项重大的挑战,尤其是对于需要多模态理解的应用。零样本学习、图像字幕生成、可视化搜索、内容调节和多模态交互等用例需要那些能够准确解释和集成视觉与文本数据的强大模型。
对比语言-图像预训练(CLIP)模型应对这一挑战的方法是采用双编码器架构同时处理图像和文本。通过对比学习,CLIP 可最大程度地提高正确图像-文本对之间的相似性,同时最大程度地降低错误图像-文本对之间的相似性,从而使该模型能够学习反映各种概念的通用表示方法。
该方法使 CLIP 能够在各种应用中大显身手,例如生成描述性图像说明文字、根据文本查询执行视觉搜索、实现零样本学习等。尤其是在零样本学习中,模型可以利用其学习到的表示方式,将图像归类成从未见过的类别。
通过 TAO 实现的 NVCLIP
在 TAO 中,我们在 NVIDIA 数据集上提供了一个由预训练 TensorRT 加速的 CLIP 模型。我们使用约 7 亿张图像训练该模型,并在评估时使用了 ImageNet 数据集中的 5 万张验证图像。
您可以将该模型从 NVIDIA Jetson 部署到 NVIDIA Ampere 架构 GPU 上。

表 5. NVCLIP 使用 ViT-H-336 和 ViT-L-336 骨干网络时的零样本 ImageNet 验证精度
SEGIC 模型
通过 NVIDIA TAO 5.5 实现全新基础模型和增强训练功能
SEGIC 是一个创新的端到端上下文分割框架,该框架利用单一视觉基础模型 (VFM)彻底改变了上下文分割。
不同于传统方法,SEGIC 可捕捉目标图像与上下文示例之间的密集关系,通过提取几何、视觉和元指令,为最终的掩码预测提供指导。该方法在大大降低标注和训练成本的同时,也在单样本分割基准测试中展现出领先的性能。
SEGIC 的多功能性可扩展到各种任务,包括视频对象分割和开放词汇分割等,这使其成为图像分割领域的一个强大工具。
通过 TAO 实现的 SEGIC
为了在 TAO 中训练 SEGIC 模型,我们提供了一个预训练 ONNX 模型和一个使用 NVIDIA Triton 推理服务器的部署方案。在训练过程中,我们使用了以下资源:

表 6. 使用 COCO20i 数据集评估的 SEGIC 模型的关键性能指标
FoundationPose 模型
通过 NVIDIA TAO 5.5 实现全新基础模型和增强训练功能
准确的 6D 物体姿态估计和追踪对机器人、增强现实和自动驾驶等各种应用至关重要。但现有的方法通常需要进行大量微调,并且受限于对基于模型的设置或无模型设置的依赖,这给在不同场景和对象中实现稳健的性能带来了挑战,尤其是在没有 CAD 模型或在处理新颖的对象时。
FoundationPose 解决这一问题的方法是提供一个同时支持基于模型的设置和无模型设置的统一 6D 物体姿态估计和追踪基础模型。它可以在测试时即时应用于新的对象,使 CAD 模型或少许参考图像得到充分的利用。
FoundationPose 采用神经隐含表示方法进行新视图合成,并使用 LLM、基于 Transformer 的新型架构、对比学习等先进技术,来进行大规模合成训练,因此具有很强的通用性,在各种公共数据集上的表现优于专用方法。
例如在增强现实应用中,FoundationPose 无需进行大量手动调整,就可以准确估计和追踪对象的姿态,从而实现虚拟对象与现实环境的无缝集成。
通过 TAO 实现的 FoundationPose
我们提供了一个预训练 ONNX 模型和一个使用 NVIDIA Triton 推理服务器的部署方案。我们的训练数据由高质量、逼真的渲染场景组成,使用的 3D 资产来自 Google Research 和 Objaverse 的扫描对象。每个数据点都包含 RGB 图像、深度信息、对象姿态、摄像头姿态、实例分割和 2D 边界框,并进行了大量域随机化。然后,我们使用 NVIDIA Isaac Sim 创建了约 100 万张合成图像。
截至 2024 年 3 月,基于模型的新颖对象姿态估计在全球 BOP 排行榜上排名第一(图 3)。
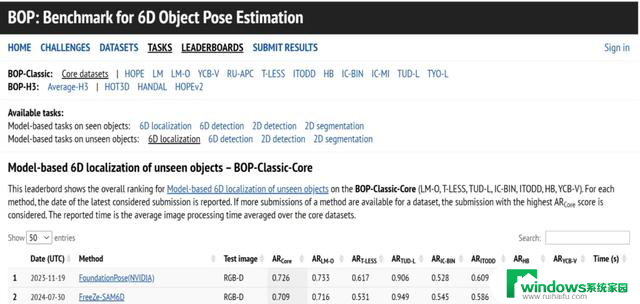
图 3. 6D 对象姿态估计基准测试
基于提示的自动标记
助力对象检测和分割
拥有一个经过良好标记的数据集对于模型训练和微调至关重要,尤其是在对象检测和分割等任务中。但为新类别和新实例获取标记数据集需要花费大量时间和精力,这一点在实例分割中尤为明显。在这种情况下,为每个对象标注精确掩码的时间最多可能要比绘制简单的边界框长 10 倍。
这时,一种简单易用、基于提示的自动标记方法能够助您一臂之力:
该组合大大减少了创建详细标签所需的工作量,从而能够更轻松、快速地建立用于训练先进模型的强大数据集。
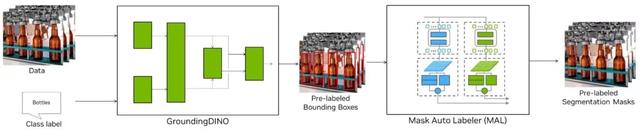
图 4. 使用 GroundingDINO 模型和掩码 自动标记工具进行自动标记
我们提供了一个无需编码就能自动标记的完整端到端 Jupyter notebook (text2box.ipynb)。我们还提供了两个规范文件,一个用于 bbox 标签,另一个用于分割,您可以在其中定义需要标记的对象,例如[人、头盔]、未标记数据集的路径,以及存储标签的结果目录。
通过 NVIDIA TAO 5.5 实现全新基础模型和增强训练功能
使用 generate 命令生成自动标签:
学生模型训练完成后,您可以使用 TAO evaluate 工具评估提炼的模型、使用 inference 工具实现推理可视化、使用 export 工具将训练完毕的模型导出至 ONNX,并最终生成 gen_trt_engine 文件,将 DINO 和 ResNet-50 模型导出至 TensorRT。
开始使用 TAO 5.5
世界各地的开发者正在使用 NVIDIA TAO 加速其视觉 AI 应用的 AI 训练。您可以使用 TAO 5.5 的新功能来加强 AI 应用。
如要了解更多信息,请访问以下资源: