微软多模态新作横扫12类任务,实现“在所有事情上打败所有人”
(素材均为网络素材,如有侵权请联系立即删除)
标题:微软BEiT-3:多模态领域的综合崛起
导语:
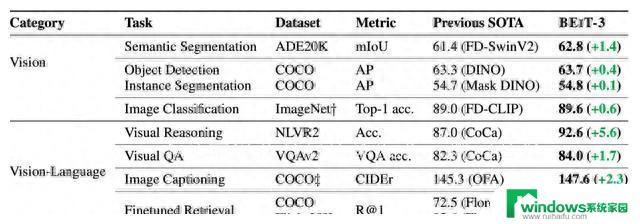
最近,微软一篇名为BEiT-3的多模态论文在学界引起轩然大波。这篇论文通过将图像视作一种外语,提出了一种新的多模态预训练方法,取得了惊人的成果。仅使用19亿参数和公共数据集,在12个任务上横扫SOTA,成为业内瞩目的焦点。在这篇文章中,我们将深入探讨BEiT-3的核心思想、方法以及其在多模态学习领域的重要地位。

从视觉自监督到多模态统一:BEiT的发展历程
BEiT系列的发展可追溯到其早期的视觉自监督学习方法。其核心思想借鉴了何恺明的MAE,提出了一种对图像进行掩码-预测的预训练任务,用于视觉任务中的自监督学习。然而,初代BEiT在性能上稍逊于MAE,因此团队持续探索,逐渐发展出了更为出色的版本。
多模态统一预训练的关键思想
BEiT-3的突破在于将图像与文本数据视为平行语料,通过共享注意力和统一预训练任务处理多模态和纯视觉任务。
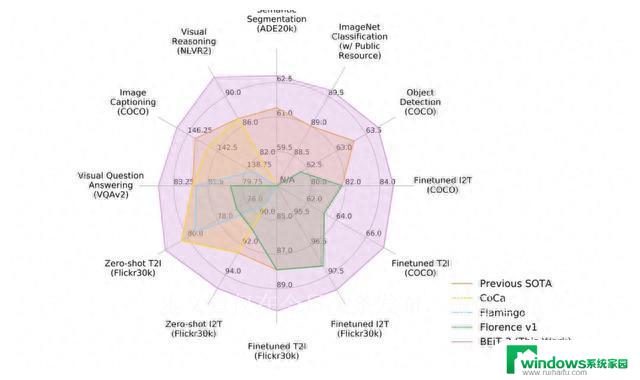
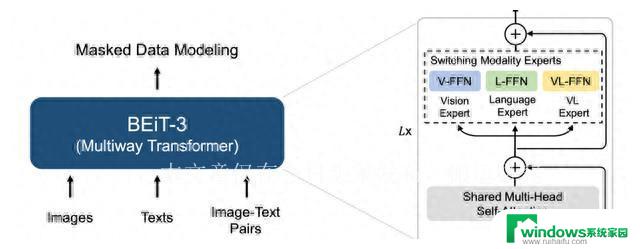
这一“大一统”的概念在网络架构、预训练方法和规模效应三个层面得以体现。团队采用Multiway Transformer架构作为骨干网络,通过共享多头自注意力层。实现不同任务的参数共享,然后在任务专用的FFN层中进行个性化处理。新的预训练方法Masked Data Modeling将所有数据都当作文本数据处理,并利用掩码-预测进行预训练,这在一定程度上减小了显存消耗。

规模效应方面,统一预训练任务使得模型参数增大,从而增强了泛化能力,同时各模态数据集也因此产生规模效应,使模型性能得到提升。
BEiT-3的综合表现
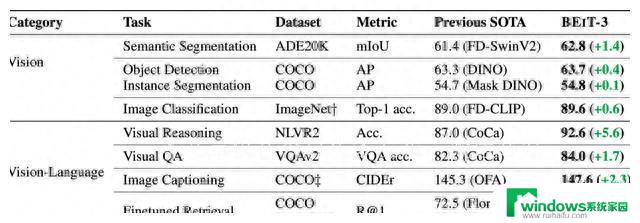
BEiT-3在纯视觉任务和多模态任务中都实现了SOTA的突破,包括图像分类、目标检测、语义分割、视觉推理、视觉问答、图像描述等任务。这种全面超越的表现,得益于BEiT-3独特的方法和多模态统一的思想。此外,虽然BEiT-3的论文篇幅仅有9页,但其取得的成就却不仅仅是自身的突破,也为视觉大规模预训练领域开辟了新的可能性。
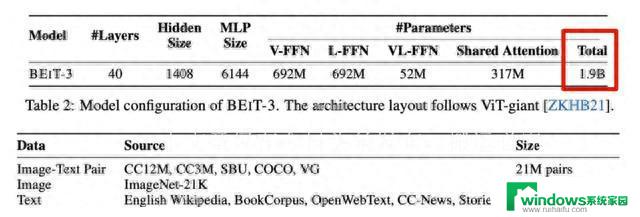
展望与总结
微软BEiT-3的成功在于将图像视为一种外语,以及其独特的多模态统一预训练方法。通过网络架构的优化、新的预训练方式以及规模效应的发挥,BEiT-3在众多任务中实现了全面超越。这篇论文不仅仅是一个研究成果,更是多模态学习领域的里程碑。它展示了微软在AI科研领域的实力,并为视觉大规模预训练领域带来了新的希望与可能性。未来,我们可以期待更多创新性的研究,进一步推动多模态学习领域的发展。

BEiT与MAE:探讨视觉自监督的不同路线
BEiT系列的发展与何恺明的MAE形成了一种有趣的对比。两者都采用了“先掩码再预测”的预训练任务,然而区别在于BEiT在图像中引入了离散化的token表示,并通过预测token来进行自监督学习。而MAE则直接预测原始像素,显得更为直接和简单。虽然初代BEiT在性能上稍逊于MAE,并在计算速度上有些不足,但BEiT团队并未止步于此,而是继续深入探索。
从VL-BEiT到BEiTv2:多模态的探索之旅
BEiT系列的发展不仅仅是在视觉领域取得进步,还包括了多模态方向。VL-BEiT作为BEiT的前身,已经奠定了共享Attention层和不同任务的专用FFN层的架构基础。然而,它在预训练任务上仍然相对复杂,需要分别处理文本和图像数据。随后,BEiTv2引入了矢量量化和知识蒸馏来训练tokenizer,提升了token中携带的语义信息,从而在纯视觉任务上重回SOTA。

这一发展过程为BEiT-3的出现铺平了道路。
BEiT-3:多模态领域的综合崛起
BEiT-3在多模态学习领域的成功标志着其系列发展的集大成。通过“大一统”的思想,BEiT-3能够在多模态任务和纯视觉任务中取得卓越表现,展示了其卓越的性能。这篇论文不仅代表了团队的努力,还将多模态学习领域推向了新的高度。
未来展望
BEiT-3的成功对于整个AI研究领域都具有重要意义。
微软团队的创新方法以及在多模态领域的综合崛起,将激励更多研究人员继续探索新的可能性。未来,我们有理由相信,多模态学习将在各种领域发挥更大作用,推动人工智能领域的进一步发展。
结语
微软BEiT-3的突破是多模态学习领域的一个重要里程碑,其创新思想和方法为该领域带来了新的启示。通过将图像视作一种外语,并采用“大一统”的预训练方式,BEiT-3在众多任务上取得了全面超越。