PPIO上线H200 SXM、RTX 5090两款显卡 | 限时折扣进行中,专属优惠等你来抢购!
更新时间:2025-06-10 13:44:34作者:ruihaifu
在模型推理、训练过程中,显卡性能至关重要。显卡的 CUDA 核心、Tensor 核心数量及架构直接影响并行计算效率,高算力显卡可显著加速模型训练与推理过程。因此,高性能、高性价比显卡成了 AI 推理训练的“必争之地”。
为助力 AI 开发者突破算力瓶颈,PPIO 全新上线 H200 SXM、RTX 5090 两款高性能显卡,即开即用,可按需付费。结合推理优化加速技术,开发者可实现资源成本的最优化。
目前,多款卡型限时折扣进行中,点击阅读原文前往 PPIO 官网算力市场即可查看。
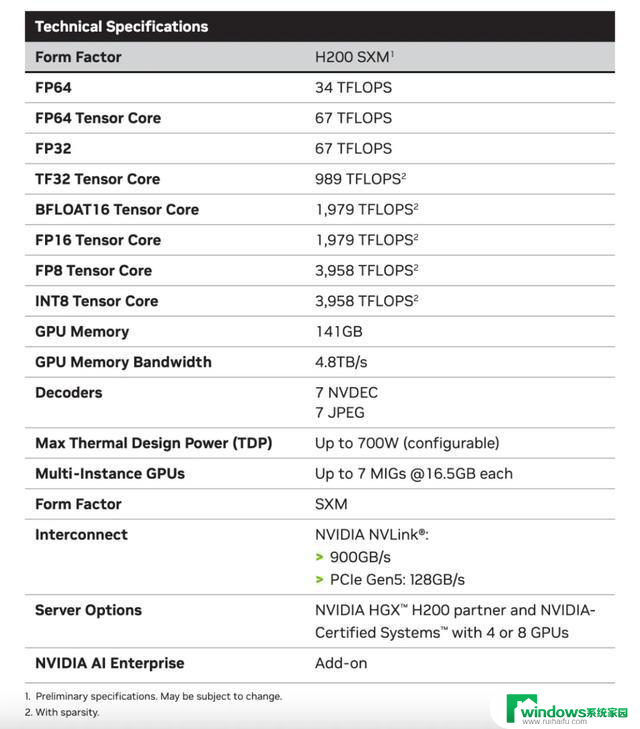
NVIDIA H200 是首款采用HBM3e的GPU,显存规格141GB。带宽达 4.8TB/秒,显著高于 H100 3.35TB/秒 的带宽。
并且,H200 具备超过 460 万亿次的浮点运算能力,可支持大规模的AI模型训练及复杂推理任务。据官方表示,与 H100 相比,H200 推理 700 亿参数的 Llama2 模型的速度是 H100 的 1.9 倍,能耗仅为 H100 的 50%。
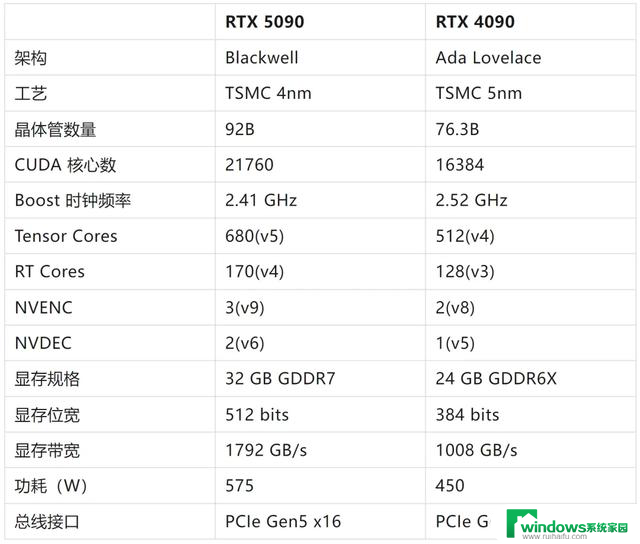
RTX 5090 基于英伟达 Blackwell 架构,相比 RTX 4090 性能提升显著。
RTX 5090 的 CUDA 核心数增至 21760,显存升级至 32GB GDDR7,带宽 1.8TB/s,对比 RTX 4090 的 24GB GDDR6X,1.0TB/s 带宽,显存带宽提升近 80%,可大幅缩短数据从显存到计算单元的传输耗时,加速模型训练。
再加上英伟达专为深度学习和人工智能设计的 Tensor Cores,RTX 5090 在 AI 模型训练和图像处理方面表现同样优异。
此外,RTX 5090 基于 Blackwell 架构设计,可支持超大规模参数的模型训练与大语言模型(LLM)实时推理任务,为 AI 研究开辟了新的可能。
PPIO 致力于为新一代生成式 AI、云渲染、机器学习和加速计算等场景提供高性价比的算力服务,目前已上线 H100、A100、H20 等多款主流卡型,登录 PPIO 官网算力市场即可查看。















